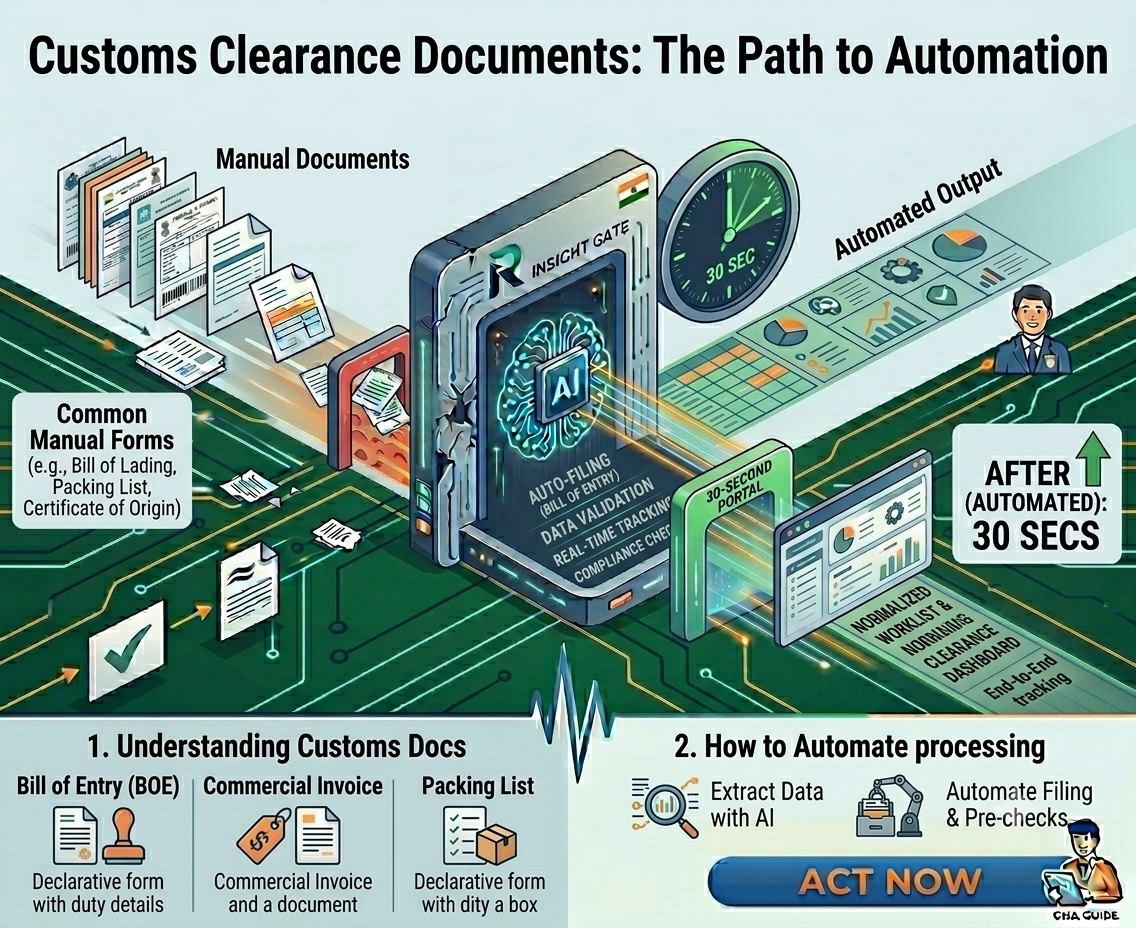
A shipment is ready to move. The commercial invoice has arrived. The packing list is buried in an email thread. The Bill of Lading is in PDF format. A certificate of origin is attached separately. Now someone on your team has to open every document, find the required fields, verify they match, and manually enter the information into your customs filing system.
For most Customs House Agents (CHAs), freight forwarders, and customs brokers, this process happens hundreds of times every month.
The problem isn’t just the time it takes. Every manually entered field creates an opportunity for errors, rework, customs queries, delayed clearances, and frustrated clients. As shipment volumes grow, document processing often becomes the biggest operational bottleneck in customs clearance.
This is where AI-powered customs document automation is transforming the industry. Instead of spending hours extracting information from invoices, packing lists, Bills of Lading, and certificates, customs teams can now process documents in seconds with higher accuracy and far less manual effort.
Before exploring how AI works, let’s first understand the documents that drive every import and export transaction.
What Are Customs Clearance Documents?
Customs clearance documents are the records required by customs authorities to verify the nature, value, origin, and compliance status of imported or exported goods.
While requirements vary by country and shipment type, the most common customs clearance documents include:
1. Commercial Invoice
The commercial invoice provides details about the buyer, seller, goods being shipped, quantity, value, currency, and payment terms.
2. Packing List
A packing list contains information about package contents, dimensions, weight, carton counts, and shipment configuration.
3. Bill of Lading (B/L) or Air Waybill (AWB)
This transportation document serves as proof of shipment and contains carrier, consignee, vessel, and cargo details.
4. Certificate of Origin
The certificate of origin identifies the country where the goods were manufactured and may impact duty calculations under trade agreements.
5. Import or Export Licenses
Certain regulated goods require permits or licenses before customs clearance can be completed.
6. Insurance Certificate
This document confirms insurance coverage for goods during transit.
7. Bill of Entry or Shipping Bill
These are the primary customs declarations filed with customs authorities for imports and exports.
8. Additional Compliance Documents
Depending on the cargo, customs may require inspection certificates, product certifications, phytosanitary certificates, test reports, or regulatory approvals.
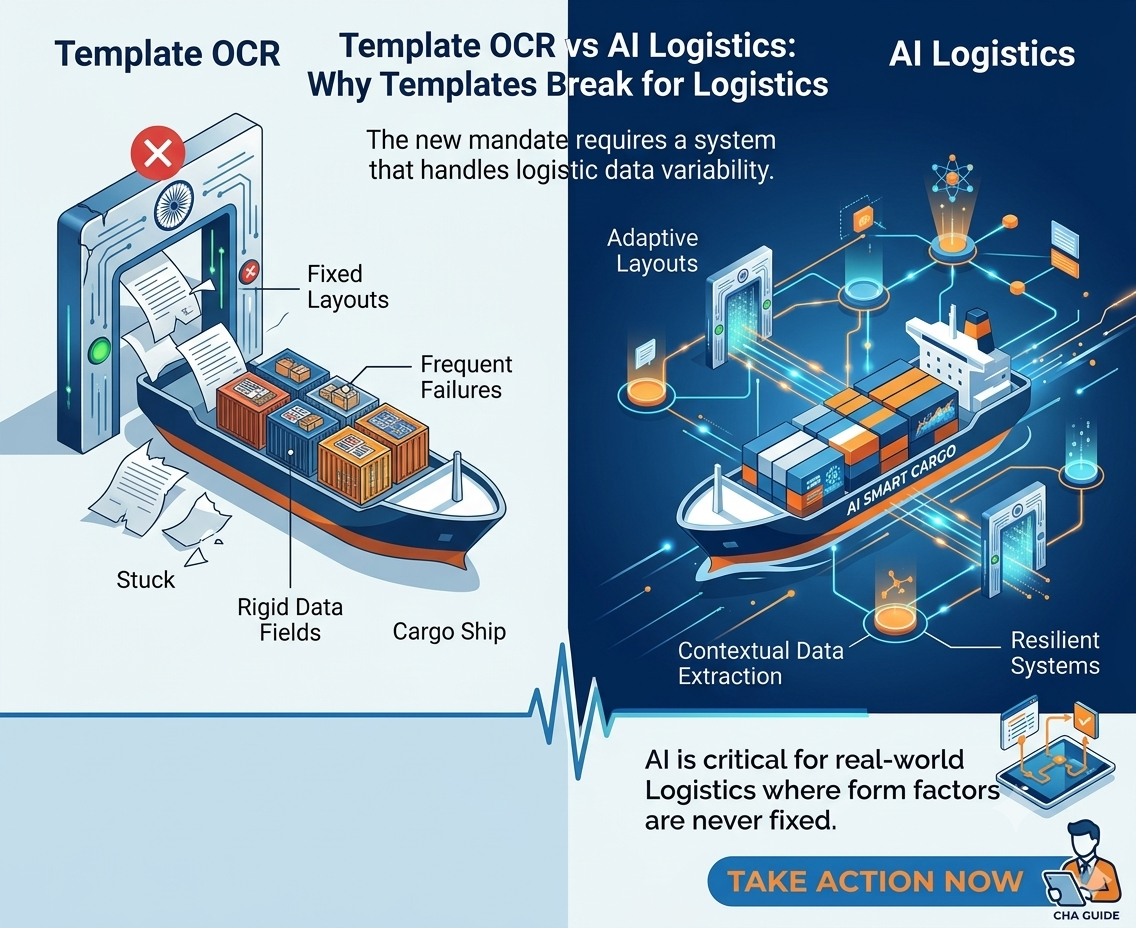
Why Customs Document Processing Is Challenging
A single shipment may involve five to ten different documents from multiple sources. Each document arrives in a different format, layout, or language.
Customs teams must:
- Read each document manually
- Extract shipment details
- Verify consistency across documents
- Identify missing information
- Enter data into customs filing systems
- Respond to customs queries and corrections
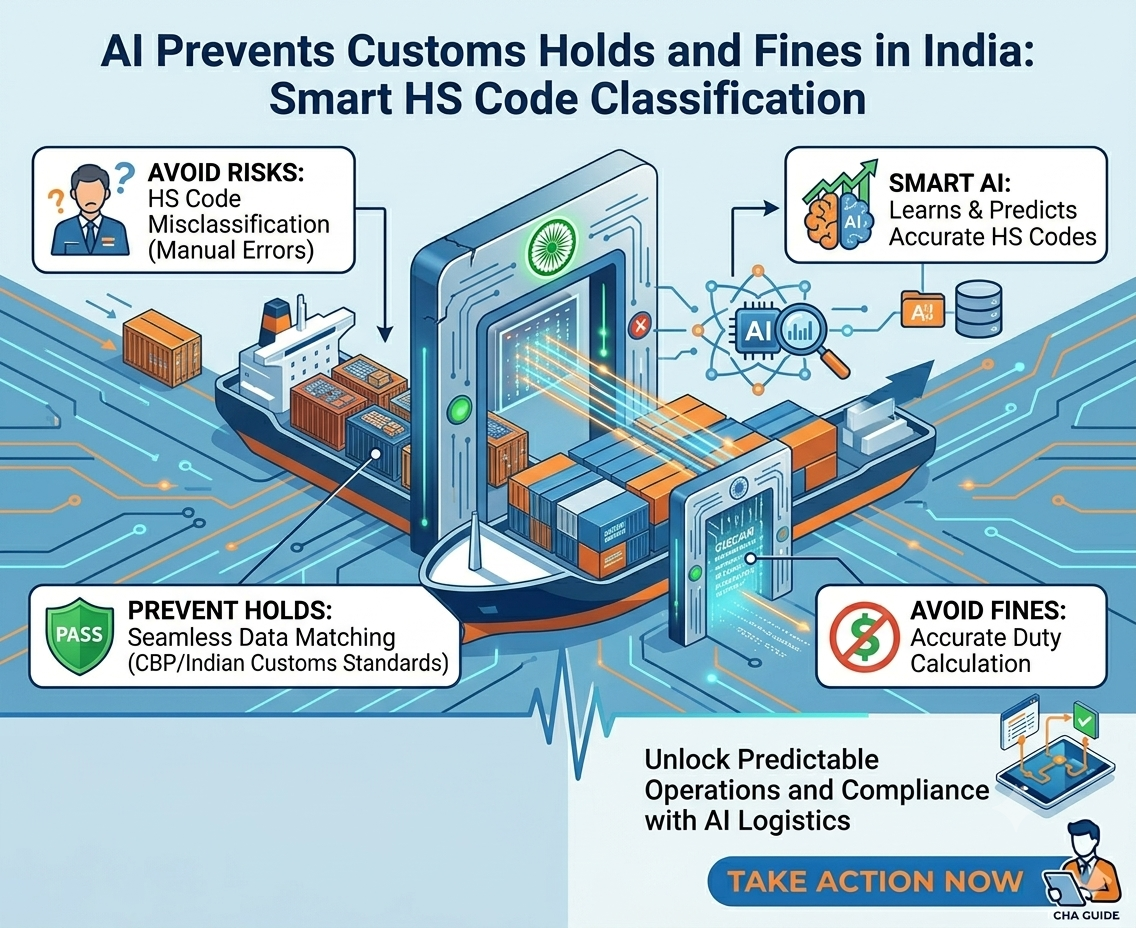
Even small errors can create significant delays. A mismatched invoice value, incorrect HS Code, or missing consignee detail can trigger customs holds, assessment queries, rework, and delayed cargo release.
As shipment volumes increase, manual processing becomes a major operational bottleneck.
Still Entering Customs Data Manually. See how Consigents Can Extract and Validate Data in SecondsHow an IDP Solution Automates Customs Clearance Document Processing
Modern AI document processing platforms use technologies such as Intelligent Document Processing (IDP), Optical Character Recognition (OCR), Large Language Models (LLMs), and machine learning to automate document handling.
Step 1: Automatic Document Classification
AI automatically identifies document types, including commercial invoices, packing lists, bills of lading, certificates of origin, and other customs documents.
No manual sorting is required.
Step 2: Data Extraction
The system extracts key fields such as:
- Importer and exporter details
- Consignee information
- HS Codes
- Product descriptions
- Invoice values
- Container numbers
- Vessel information
- Country of origin
- Gross and net weights
Instead of manually entering dozens of fields, users receive structured data instantly.
Step 3: Cross-Document Validation
AI compares information across multiple documents and flags discrepancies.
For example:
- Invoice quantity differs from packing list quantity
- Country of origin does not match supporting documents
- Container numbers are inconsistent
- Product descriptions vary between forms
These checks help prevent filing errors before submission.
Step 4: Exception Handling
Only documents with missing data, inconsistencies, or low-confidence fields are routed to human reviewers.
Teams spend their time reviewing exceptions instead of performing repetitive data entry.
Step 5: Customs Filing Integration
Validated data can be exported directly into customs filing software, ERP systems, logistics platforms, or customs portals, reducing manual effort further.
Benefits of AI-Powered Customs Document Processing
Faster Clearance
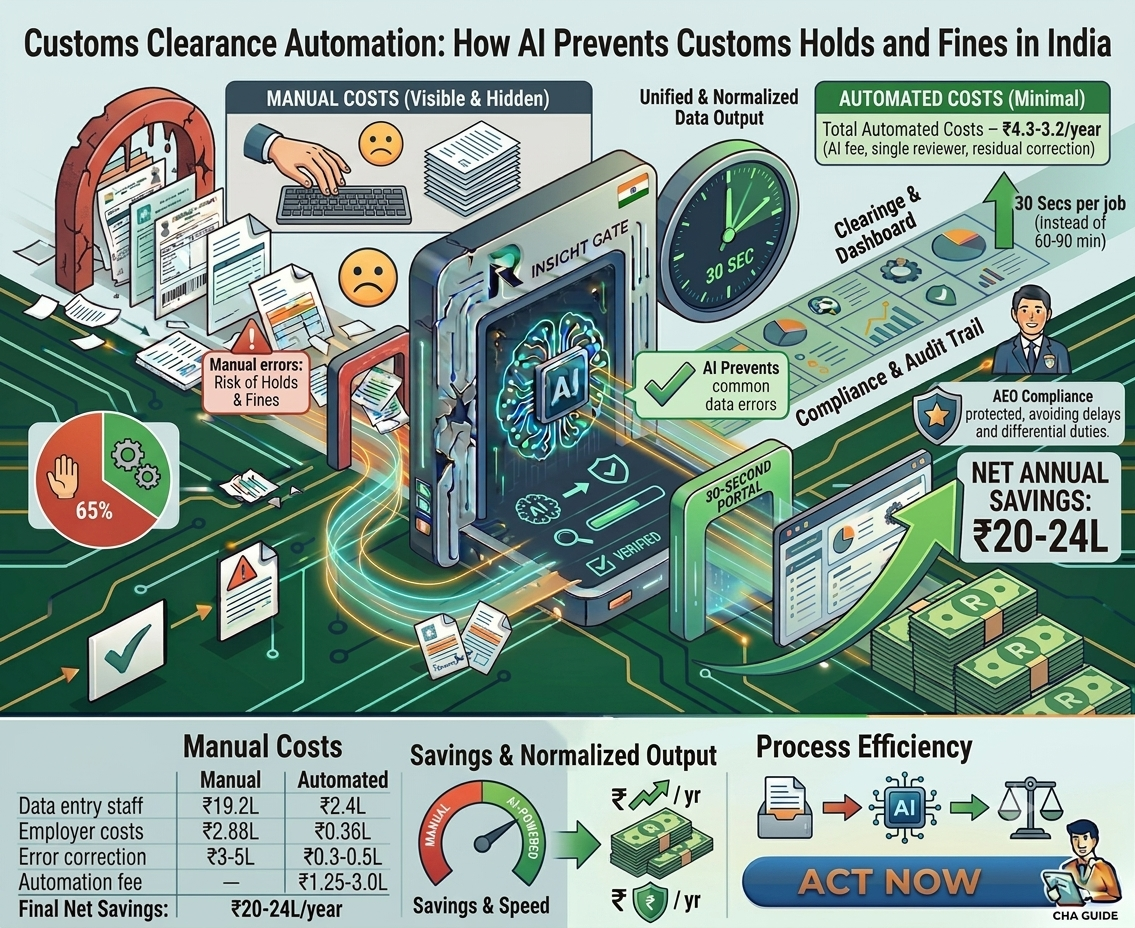
Documents that previously required 60–90 minutes of manual processing can be completed in seconds, helping accelerate customs submissions.
Higher Accuracy
AI validation reduces human data-entry errors and improves filing quality.
Reduced Operational Costs
Organizations can significantly reduce labor for document extraction and data entry, enabling staff to focus on compliance and customer service.
Better Scalability
Manual processing scales linearly with shipment volume. AI automation enables teams to handle higher volumes without increasing headcount in proportion.
Improved Compliance
Automated validation helps identify missing fields, inconsistent data, and documentation issues before customs review.
The Future of Customs Operations
Customs authorities worldwide are moving toward greater digitization, automation, and risk-based processing. Faster customs clearance increasingly depends on accurate, complete, and electronically submitted documentation.
Organizations that continue relying on manual document processing face growing challenges with speed, compliance, and scalability.
AI-powered customs document automation enables CHAs, freight forwarders, customs brokers, and logistics providers to process documents faster, reduce errors, improve compliance, and support business growth without expanding administrative teams.
Process More Shipments without Adding Headcount
Discover how Readerr helps CHAs scale with AI automation.
Book a Demo NowConclusion
Customs clearance documents are the foundation of every international shipment, but managing them manually creates delays, costs, and compliance risks.
AI-powered document processing transforms this workflow by automatically classifying documents, extracting data, validating information, and preparing customs-ready records. The result is faster clearance, fewer errors, lower operational costs, and a more scalable customs operation.
As shipment volumes continue to grow, AI is becoming an essential technology for organizations looking to modernize customs documentation and improve trade efficiency.
Frequently Asked Questions about Customs Document Automation
Customs clearance typically requires a commercial invoice, packing list, Bill of Lading or Air Waybill, certificate of origin, import or export licenses (where applicable), insurance certificate, and customs declarations such as a Bill of Entry or Shipping Bill. Additional documents may be required depending on the cargo type and destination country.
A customs clearance document is any document used by customs authorities to verify the value, origin, classification, ownership, and compliance status of imported or exported goods before approving their movement across borders.
The commercial invoice is generally considered the most important customs clearance document because it provides key information about the shipment, including product descriptions, quantities, values, buyer details, and seller details used for customs assessment and duty calculation.
AI automates customs document processing by automatically classifying documents, extracting key shipment data, validating information across multiple documents, identifying discrepancies, and preparing structured data for customs filing systems without manual data entry.
Yes, AI-powered document processing systems can extract information from Bills of Lading, commercial invoices, packing lists, certificates of origin, and other shipping documents, even when formats vary between carriers, suppliers, and trading partners.
AI-powered customs document automation helps reduce manual data entry, improve accuracy, accelerate customs filings, lower operational costs, reduce compliance risks, and enable customs teams to process higher shipment volumes without increasing headcount.
Customs House Agents use AI to automatically extract shipment information from customs documents, validate data before filing, reduce processing time, minimize filing errors, and improve overall customs clearance efficiency.
Traditional OCR converts document images into machine-readable text. AI document processing goes further by understanding document context, identifying relevant fields, extracting structured data, validating information, and handling multiple document formats without predefined templates.
Yes, AI reduces customs filing errors by automatically validating extracted data, cross-checking information across multiple documents, identifying inconsistencies, and flagging missing or suspicious values before submission.
CHAs can automate customs document processing using AI-powered document automation platforms that extract data from shipping documents, validate information across documents, and prepare customs-ready records in seconds, reducing manual effort and improving filing accuracy.